Crowdcrafting stack
Photo by Sina
Putting all your heart in what you do makes the difference. Why? Because as the Baron says in the movie, The Cat Returns, the creation is given a soul.
On December 4 of 2014, we got the very wonderful news that Crowdcrafting was recognized as one of the social technological companies of the year.
Wining this price has been amazing, a recognition to our really hard to make our Crowdcrafting site robust, scalable and stable.
TL;DR as this is going to describe our current infrastructure and how we run Crowdcrafting, so you are advised!
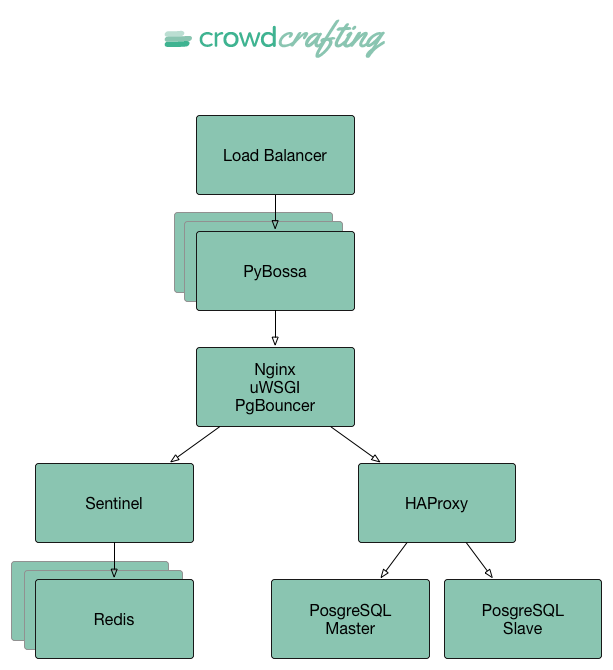
HTTP Load Balancer
We host all our services in Rackspace. The reason? Well, they’ve a handy calculator that allows us to estimate how much is going to cost us running our services there, and I love it. Basically, because they don’t lie, and the numbers fit.
One of the nice features that Rackspace offers, is the option to enable an HTTTP load balancer for your cloud servers. This simplifies a lot our set up, and we’ve configured it to balance the incoming requests to our PYBOSSA servers.
Therefore, when a user requests a page from Crowdcrafting, the first service that it’s contacted is the load balancer. The balancer will distribute the requests to our PYBOSSA servers.
Nginx & uWSGI
Once the request has been redirected to one of the PYBOSSA servers, the request hits the Nginx server. Nginx, checks its sites enabled, and directs the request to our PYBOSSA Flask application written in Python. At this point, the server is contacted and served via the uWSGI middleware, that will take care of moving the request through our infrastructure.
Hence, Nginx takes care of serving static files, while uWSGI takes care of the rest.
In the very beginning of Crowdcrafting we used Apache2 and mod_wsgi, but we changed to Nginx and uWSGI because:
When we were running on Apache2 and mod_wsgi the performance was suboptimal (we tested it with Locust.io) and we could see a clear detriment in the number of requests per second that we were delivering in comparison with the current setup. For this reason, we looked for new solutions and we found that the best match for us is Nginx + uWSGI.
While we’ve been developing PYBOSSA we’ve always keep in mind that PYBOSSA should be able to scale horizontally without problems. While this seems easy to achieve the truth is that there are so many options out there that at the end it becomes a nightmare to decide which one is the best solution.
For example, serving avatars from N different servers should always return the same image from all of them to the clients.
In our case we decided to keep things as simple as possible, (the KISS principle).
For this reason, we’ve enabled the Rackspace CDN support in PYBOSSA (it can be easily extended to any other CDN as we’ve a generic class that can be inherited) for serving files from a central place. This solution allows us to grow horizontally without taking care of where the files are being served.
Additionally, if someone does not want to enable the CDN, they can configure PYBOSSA to use the local uploader and use a Glusterfs to distribute the files across all the servers. We didn’t like this solution as it added another point for failure in our systems and we’ve to take care of it ourselves, while the CDN does this for us automagically.
Once the request is in the uWSGI middleware, the PYBOSSA server will probably need access data in the database, so it can render the HTML and return the response back to the client. The next section explains how we handle this part of the request.
PostgreSQL & PgBouncer
Once the request hits the Flask app, usually it will involve a query to the database. We use PostgreSQL 9.3 and we’re really impressed by the quality, performance and community around it. We LOVE IT! Best DB ever.

As we will have lots of connections coming from different servers, we wanted to improve how we handle those connections to the DB to reduce overhead and timing establishing connections, closing, etc. For this issue we’re using in each PYBOSSA server PgBouncer for pooling the connections to two PostgreSQL servers:
- Master node accepting read and write queries, and
- Slave node accepting only read queries.
PYBOSSA establishes two different connections to the databases in order to use read-only connections when we want to grab just information, or write connections when we’ve to write something back to the DB.
While PgBouncer pools connections, it does not load balance them, so for this reason we use HAProxy to load balance the READ queries between the master and slave nodes transparently. The best part of this configuration is that everything is completely handled automagically and transparently by HAProxy, so PYBOSSA does not know anything about it.
Thanks to this set up we can add more slave nodes horizontally, scaling and load balancing our infrastructure easily.
While this solution is great, some queries need to be cached before hitting the database as they take time to be processed (i.e. statistics for Crowdcrafting projects). For this reason we’re using Redis and Sentinel to cache almost everything.
Redis & Sentinel
If we’re in love with PostgreSQL what can we say about Redis and Sentinel: we love them too :-)

Since the very beginning PYBOSSA has been using Redis and Sentinel to build a load-balance high-available cache solution.
There set up is pretty simple: one Redis master node that accepts read and write queries, while almost every other node in our infrastructure has a slave node.
Additionally Sentinel takes care of handling all these nodes for us transparently, and we don’t have to do anything ourselves. This solution has been working great for us, and thanks to it we’re saving lots of queries from the DB, improving our performance.
More over, we are using Redis also for background jobs (i.e. exporting results, computing statistics, sending emails, etc.) thanks to Python-RQ and rq-scheduler to run periodic jobs.
We checked Celery but it was overkilling for what we are building and we decided again to keep things simple.
Python-RQ and rq-scheduler are small libraries that can be easily adapted to our needs, plus we already have in our systems Redis so it was the best candidate for us.
Summary
In summary, we’re using micro frameworks to build our project paired with a very simple infrastructure that allows us to grow horizontally without problems and load balance our incoming traffic efficiently.
The next picture shows how a request goes through our current setup:
UPDATE: Some people have asked about our numbers. The truth is that the current setup can serve up to 2.5k rpm in less than 200ms for 1500 users browsing the site at the same time (we’ve 2 PYBOSSA servers with 2GB of RAM and 2 cores each, while the DBs have 4GB of RAM and 4 cores -master and slave).
In August 2014 we managed to store in our servers more than 1.5 datum per second one day. At that moment the DB servers have only 1GB of RAM, and taking into account that the OS takes around 200MB of it, the DBs were using only 800MB of RAM.
Deployments & Ansible
Up to now we’ve been managing all our infrastructure by hand. However, in the last weeks we’ve been migrating our infrastructure to be completely controlled via Ansible.
Additionally, we’ve developed our own in-house solution for automatic deployments for all the team integrated with Github Deployments API and Slack to get notifications in our own team chat channels. Doing a deployment right now consist in merging and closing a pull request. As simple as that.

Using Ansible for everything has helped us to have similar playbooks reused across different clients, allowing us to do faster deployments that are easy to maintain, debug and deploy.
On the other hand the automatic deployments solution uses the same playbooks, so everything runs on the same tools and technologies.
We checked different solutions like HUBot, but we decided again to have a very simple solution to integrate all these tools in our toolchain. The deployments server has less than 300 lines of code, is 100% fully tested and covered, so it’s really simple to adapt it and fix it. Moreover, it runs in the same services that we are currently using: Nginx + uWSGI, so we don’t have to add anything different to our stack.
NOTE: I’ll write a blog post about the deployments solution :-) EDIT: You can read about the deployment solution here.
Continuous integration and code quality
We take really seriously code quality and tests. Right now we’ve almost 1000 tests (953 at the time of the writing) covering almost all the source code (97% covered) and with a health quality of 94%.
Our deployments solution uses the Travis-CI Github Statuses API to do the deployments, so we can know for sure that it will work in our production systems.
We follow the Github Flow more or less, as we don’t have a versioning schema per se for our PYBOSSA software. What we do is that everything that it is in master is stable, as our main service runs directly from it. For this reason, we take really seriously the quality of our software as a bug or an issue will break our Crowdcrafting platform.
We usually do several deployments per week, adding new features, bug fixes, etc. to PYBOSSA and therefore Crowdcrafting, as all the team has deployment rights. This has proven to be an amazing feature, as we deliver really fast following the RERO principle: Release Early Release Often.
And that’s all! I hope you like it. If you have questions, please, use the comments section below and I’ll try to answer you. Now:
